📊 Full opportunity report: VigilSAR Benchmark: There Is No Best Model on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The VigilSAR Benchmark shows that no AI model is the best overall; rankings depend on specific user profiles emphasizing capability, reliability, compliance, and deployability. This shifts focus from raw power to suitability for defense applications.
The VigilSAR Benchmark has released its first comprehensive evaluation showing that there is no single “best” AI model for defense and intelligence applications. Instead, model rankings depend heavily on the specific needs of the user, such as deployment environment and compliance requirements. This challenges the common perception that the most capable model is automatically the best choice for deployment, highlighting the importance of context in AI selection.
The VigilSAR Benchmark evaluates models across five axes: Capability, Reliability, Robustness, Safety & Compliance, and Efficiency & Deployability. Unlike traditional leaderboards that prioritize raw intelligence, VigilSAR emphasizes trustworthy deployment, especially in defense contexts. It scores models on their domain knowledge, consistency, safety, and ability to run on-premises or air-gapped systems, which are critical for government and military use.
Importantly, the benchmark applies different user profiles—such as cloud-centric, on-premises, or compliance-focused—and re-ranks models accordingly. For example, a model ranked highest for cloud deployment might fall lower for on-premises or compliance-sensitive users, underscoring that “best” varies with the context. The evaluation explicitly excludes harmful capabilities like weaponization or exploit generation, focusing solely on trustworthy, defense-relevant competence.
The creators emphasize that this approach aims to prevent overreliance on capability scores alone, which can be misleading for actual deployment decisions. The methodology is still evolving, and the results represent early insights into what truly matters for defense AI applications.
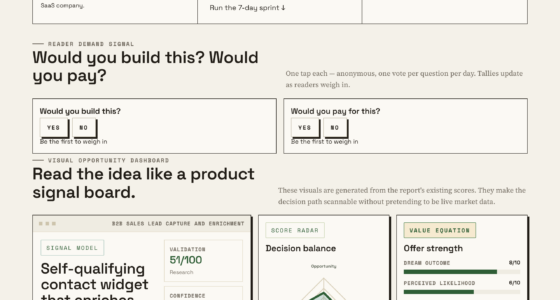
VigilSAR Benchmark — there is no best model
Capability leaderboards measure who’s smartest. This one scores who’s deployable — across five axes — then re-ranks by who’s actually asking.
Independent commentary, produced with AI assistance under human editorial oversight. The views are the author’s own and may change. VigilSAR Benchmark is an early-stage, in-development public benchmark; methodology, scope and results will evolve and are not a certification, authority, or guarantee of any model’s fitness, safety, or compliance. It scores defense-relevant competence and explicitly excludes weaponeering, targeting, CBRN, and exploit-generation tasks. Benchmark results are indicative, can be gamed or in error, and require independent verification; nothing here endorses any model. Model and company names are trademarks of their respective owners; mention does not imply endorsement.
Implications of Context-Dependent AI Rankings
This development shifts the focus from simply identifying the most capable AI models to understanding which models are suitable for specific defense and regulated environments. It highlights the importance of trustworthiness, safety, and deployability in real-world applications, especially where compliance with legal frameworks like the EU AI Act and GDPR is mandatory. For policymakers, defense agencies, and AI developers, this means that choosing an AI model requires careful consideration of the operational context rather than relying solely on capability leaderboards.
By demonstrating that model rankings are not universal, VigilSAR encourages a more nuanced approach to AI procurement and deployment, reducing risks associated with deploying powerful but unreliable or non-compliant models. This could influence future standards and procurement strategies in defense sectors worldwide, promoting safer and more responsible AI use.

Hands-On Guide to the Model Context Protocol: Building, Securing, and Scaling AI Agents in Python (The Hands-On Tech Professional Series Book 29)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Limitations and Scope of the VigilSAR Benchmark
The VigilSAR Benchmark is designed specifically for defense-relevant AI competence, deliberately excluding areas like weaponization, targeting, or exploit generation. Its scope focuses on trustworthy knowledge work, reliability, and compliance, aligning with the needs of regulated, sovereign, and defense-adjacent organizations.
It is still in early development, with the methodology subject to refinement as the team gains more insights. The current results do not represent a final authority but serve as a foundation for understanding how different models perform under varied operational constraints. The benchmark also aims to promote provider-agnostic evaluation, avoiding lock-in to specific vendors or models.
Most existing leaderboards prioritize raw performance metrics, often ignoring deployment realities, which VigilSAR explicitly addresses. Its approach aims to fill a critical gap in AI evaluation for sensitive, regulated environments.
“There is no single ‘best’ model; the right choice depends on the specific operational context and user needs.”
— Thorsten Meyer, lead researcher
trusted AI model for government use
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Uncertainties About Benchmark Evolution and Adoption
As the VigilSAR Benchmark is still in early development, it remains unclear how its methodology will evolve and how widely it will be adopted by defense agencies and industry. The exact weighting of axes and profiles may change as more data and feedback are incorporated. Additionally, its ability to influence procurement standards and industry practices is yet to be seen, especially outside initial pilot users.
on-premises AI hardware for defense
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps for Validation and Broader Adoption
The VigilSAR team plans to refine its methodology through ongoing testing and community feedback. Further publications are expected to explore additional profiles and axes, aiming to establish a more comprehensive and standardized evaluation framework. Engagement with defense and regulatory bodies will be crucial to promote adoption and integrate the benchmark into procurement processes.
In parallel, the team will monitor how different models perform under real-world deployment scenarios, adjusting the evaluation criteria accordingly. The goal is to develop a flexible, transparent, and practical tool for selecting AI models aligned with operational needs.

AI Forensics
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why is there no single ‘best’ AI model according to VigilSAR?
The benchmark shows that the most suitable model varies depending on the user’s operational environment, compliance needs, and deployment constraints. No one model excels across all axes for all profiles.
How does VigilSAR differ from traditional AI leaderboards?
Unlike traditional leaderboards that focus solely on capability or performance metrics, VigilSAR emphasizes trustworthiness, safety, robustness, and deployability, especially in regulated defense contexts.
Can this benchmark influence defense procurement decisions?
Yes, by providing a more nuanced evaluation tailored to operational needs, VigilSAR aims to help defense agencies select models that are both effective and compliant, reducing deployment risks.
What are the limitations of the current VigilSAR evaluation?
The methodology is still evolving, and the benchmark currently covers a limited set of axes and profiles. Its long-term impact depends on further validation and industry adoption.
Will the benchmark include assessments of harmful capabilities in the future?
No, VigilSAR explicitly excludes harmful capabilities like weaponization or exploit generation, focusing instead on trustworthy, defense-relevant knowledge work.
Source: ThorstenMeyerAI.com